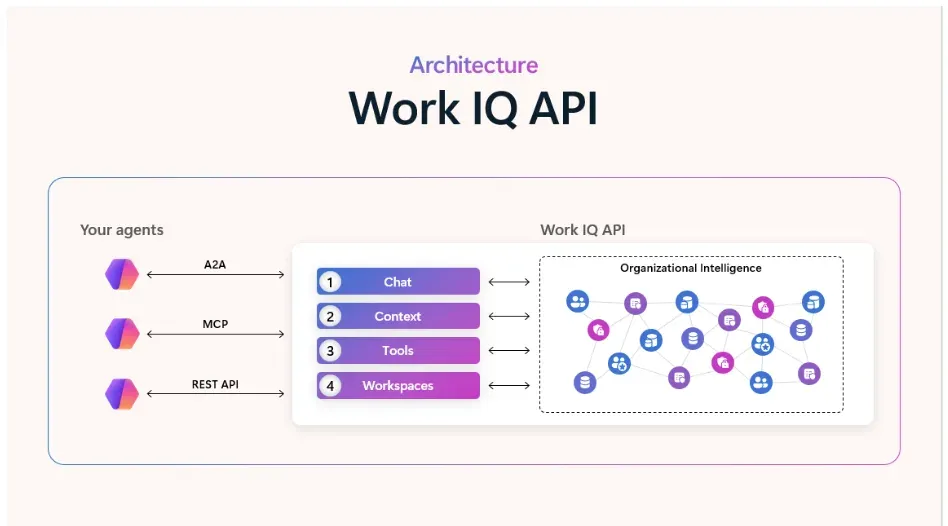
Představujeme multimodální inteligenci v Researcher
Researcher nyní přichází se dvěma novými multimodálními funkcemi, které posouvají laťku v přesnosti, hloubce a spolehlivosti AI generovaných reportů: Critique…
Researcher – agent pro hloubkový průzkum v Microsoft 365 Copilot pro pracovní scénáře – dnes posouvá laťku zase o kus výš. Je navržený tak, aby zvládal složitý research přímo v rámci Vaší práce, a nově přidává dvě multi-model funkce, které zvyšují přesnost, hloubku i jistotu výsledků: Critique a Council.
Critique je nový multi-model systém pro hloubkový research určený pro náročné úkoly. Odděluje generování od hodnocení a kombinuje modely z Frontier labs, včetně Anthropic a OpenAI. Jeden model vede fázi generování – naplánuje postup, iteruje vyhledávání a připraví první návrh – zatímco druhý model se soustředí na kontrolu a vylepšení, funguje jako expertní reviewer ještě před vytvořením finálního reportu. Podle interních vyhodnocení tato architektura překonává tradiční přístup s jedním modelem a přináší špičkovou kvalitu deep research. Návrh zároveň jasně odděluje role generator a reviewer a umožňuje je postupně rozšiřovat a posilovat s tím, jak se bude systém dál vyvíjet.
![Skóre benchmarku DRACO (Deep Research Accuracy, Completeness, and Objectivity) napříč 100 komplexními research úlohami v 10 doménách. Všechny výsledky pocházejí z původního článku [Zhong et al., arXiv:2602.11685 (únor 2026)], kromě Researcher with Critique. Researcher with Critique dosahuje výrazného zlepšení o +7,0 bodu (SEM ±1,90) v agregovaném skóre, tj. o +13,88 % oproti Perplexity Deep Research (model Claude Opus 4.6), nejlepšímu systému uvedenému v článku.](https://stainewsortymfczbpzju.blob.core.windows.net/content/2026/05/image-87849d44.png)
Skóre benchmarku DRACO (Deep Research Accuracy, Completeness, and Objectivity) napříč 100 komplexními research úlohami v 10 doménách. Všechny výsledky pocházejí z původního článku [Zhong et al., arXiv:2602.11685 (únor 2026)], kromě Researcher with Critique. Researcher with Critique dosahuje výrazného zlepšení o +7,0 bodu (SEM ±1,90) v agregovaném skóre, tj. o +13,88 % oproti Perplexity Deep Research (model Claude Opus 4.6), nejlepšímu systému uvedenému v článku.
Council v prostředí Researcher zobrazuje odpovědi z více modelů vedle sebe. Součástí je také cover letter, který přehledně ukáže, v čem se modely shodují, kde se jejich závěry rozcházejí a jaké jedinečné pohledy každý z nich k tématu přináší.
Critique a jak funguje
Řada AI workflow pro výzkum spoléhá na jeden model, který zvládá plánování, vyhledávání zdrojů, syntézu i samotné psaní. Critique na to jde jinak: rozděluje práci mezi dva AI „parťáky“ – jeden je optimalizovaný na hlubší průzkum a strukturovanou syntézu, druhý se soustředí na ověřování tvrzení, vylepšení prezentace a posílení struktury. Tím, že hodnocení dostává stejnou váhu jako generování, vzniká účinná zpětnovazební smyčka, která zvyšuje kvalitu výsledků z hlediska faktické přesnosti, šíře analýzy i celkové prezentace. Critique bude ve Researcher výchozí režim a bude dostupný při volbě Auto v model pickeru.
Critique používá proces kontroly podobný tomu, jaký se běžně uplatňuje v akademickém i profesionálním výzkumu. Stojí na rubric‑based evaluation – strukturovaném hodnocení podle jasných kritérií, jehož cílem je zprávu posílit, aniž by se z hodnotitele stal „druhý autor“. Hodnotitel se na report dívá z několika úhlů a následně vytvoří vylepšenou verzi se zaměřením na tyto oblasti:
- Source Reliability Assessment. Hodnotitel klade důraz na použití důvěryhodných, autoritativních a pro danou oblast vhodných zdrojů a upřednostňuje důkazy, které lze ověřit a které odpovídají kontextu Vašeho zadání.
- Report Completeness. Hodnotitel posuzuje, zda finální report komplexně naplňuje záměr Vašeho požadavku a přináší relevantní a jedinečné poznatky.
- Strict Evidence Grounding Enforcement. Hodnotitel uplatňuje konzervativní standard pro opření tvrzení o důkazy: každé klíčové tvrzení musí být podložené spolehlivými zdroji s přesnými citacemi – což zvyšuje faktickou přesnost, spolehlivost i důvěru ve finální report.
Ověření výkonu na benchmarku DRACO
Microsoft otestoval Critique na benchmarku DRACO (Deep Research Accuracy, Completeness, and Objectivity) – jde o 100 náročných deep research úloh napříč 10 doménami, které v únoru 2026 představili výzkumníci z Perplexity a akademické sféry [Zhong et al.arXiv:2602.11685]. Tyto úlohy vycházejí z anonymizovaných vzorců reálného používání ve velkém výzkumném systému. Odpovědi systému se hodnotí podle rubrik specifických pro daný úkol ve čtyřech dimenzích: faktická správnost, šířka a hloubka analýzy, kvalita prezentace a kvalita citací.
Výsledky DRACO se vyhodnocovaly pomocí OpenAI GPT-5.2 jako LLM judge – nejpřísnějšího ze tří hodnoticích modelů uvedených v článku. Microsoft použil stejný evaluační protokol a konfiguraci jako v benchmark paperu, aby bylo srovnání skutečně férové. Ve všech metrikách se výsledky počítaly jako průměr přes celý dataset DRACO, přičemž každá otázka se vyhodnocovala v pěti nezávislých bězích.
Aby bylo jasnější, v čem Critique pomáhá, Microsoft porovnal novou architekturu s původním single-model Researcher (se stejným GPT-5.2 judge) napříč čtyřmi hodnoticími osami, které DRACO definuje.
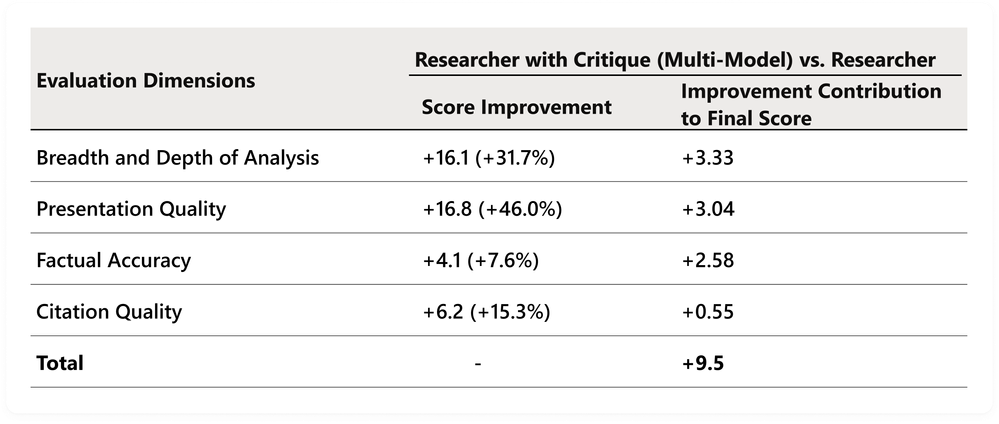
Největší posun je vidět u Breadth and Depth of Analysis (+3,33), následovaný Presentation Quality (+3,04) a Factual Accuracy (+2,58). Ve všech dimenzích jde o statisticky významné zlepšení (paired t-test, p < 0,0001).
Critique vede Researcher k tomu, aby dohledal chybějící analytické úhly, doplnil mezery v pokrytí, zpřesnil formulace a generoval odpovědi s lepší strukturou a srozumitelnějším tokem argumentace. To vysvětluje výrazné zlepšení ve skóre šířky/hloubky i kvality prezentace. Nárůst faktické správnosti ukazuje, že Critique zpochybňuje slabá tvrzení a tlačí na vyšší přesnost. Zlepšení v Citation Quality je hlavně o lepším využití už dostupných zdrojů – nová vrstva klade důraz na výběr důkazů a citování, ne na rozšiřování počtu zdrojů.
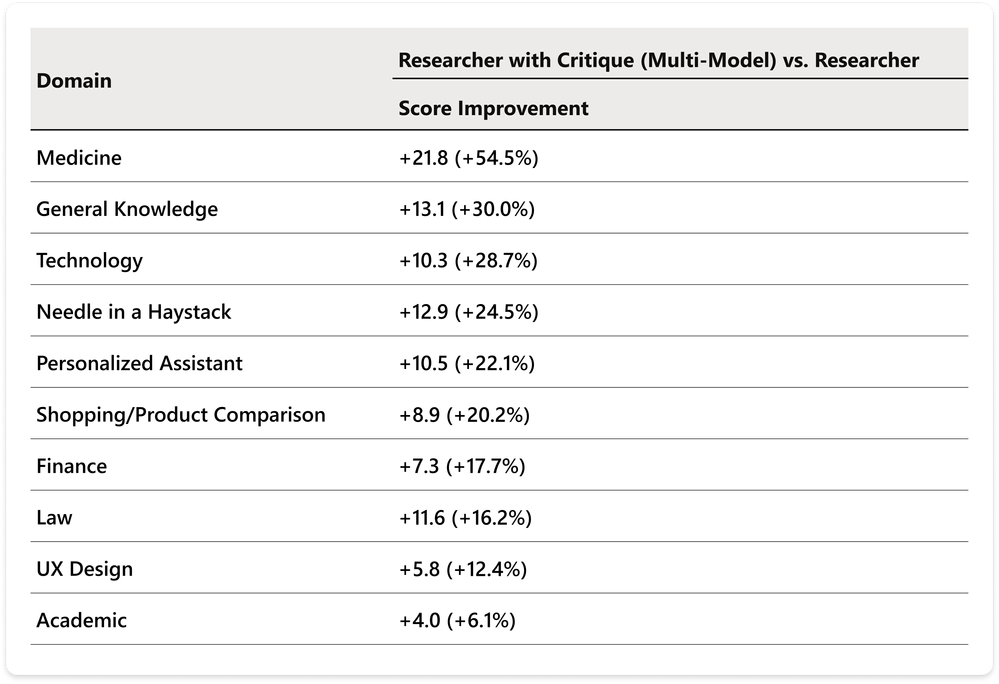
Sada dotazů DRACO pokrývá 10 domén napříč medicínou, technologiemi, právem a dalšími oblastmi. Researcher s Critique dosahuje vyšších skóre než single-model přístup napříč doménami, což potvrzuje přínos Critique jako „horizontální“ vrstvy kvality pro Researcher. Na úrovni domén jsou statisticky významná zlepšení v 8 z 10 oblastí (paired t-test, p < 0,05). Výjimkou jsou Academic (p=0,27) a Needle-in-a-Haystack (p=0,16), kde se projevuje vysoká variabilita.
Council a jak funguje
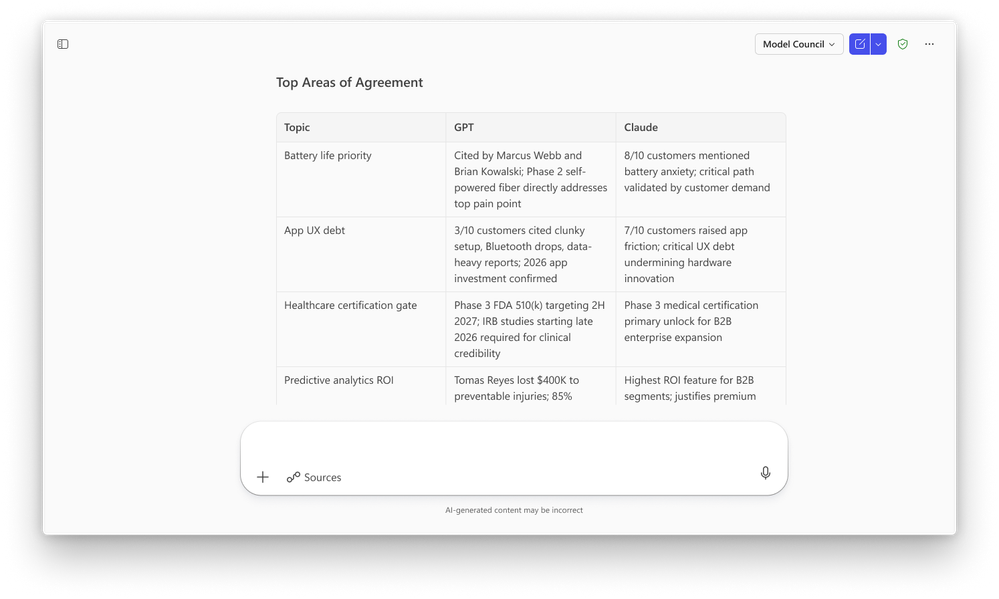
Council je alternativní režim navržený pro přímé srovnání více modelů vedle sebe. Když v Researcher v model pickeru zvolíte Model Council, Council spustí současně modely od Anthropic a OpenAI. Každý z nich vytvoří kompletní, samostatný report – včetně faktů, citací a analytického pohledu, který může ten druhý opomenout nebo vyhodnotit jinak. Jakmile jsou oba reporty hotové, vyhrazený judge model je vyhodnotí a připraví zhuštěné shrnutí hlavních zjištění. Zároveň jasně ukáže, v čem se modely podstatně shodují nebo rozcházejí – ať už jde o rozdíly v míře, způsobu rámování nebo interpretaci – a vypíchne jedinečné přínosy každého z nich.
Začněte s Critique a Council v Researcher
Critique a Council jsou nyní široce dostupné v rámci Frontier program. Podívejte se, jak nastartovat Frontier Transformation s Copilot a agenty, a vyzkoušejte možnosti multi-model intelligence.
Tento článek vznikl s využitím materiálu z techcommunity.microsoft.com. Osobní postřehy a komentáře jsou moje vlastní.